The
object-oriented paradigm is a new and different way of thinking about
programming and many folks have trouble at first knowing how to approach a
project. Now that you know that everything is supposed to be an object, and as
you learn to think more in an object-oriented style, you can begin to create
“good” designs, ones that will take advantage of all the benefits
that OOP has to offer.
A
method
(also often called a
methodology)is
a set of processes and heuristics used to break down the complexity of a
programming problem. Many OOP methods have been formulated since the dawn of
object-oriented programming, and this section will give you a feel for what
you’re trying to accomplish when using a method.
Especially
in OOP, methodology is a field of many experiments, so it is important to
understand what problem the method is trying to solve before you consider
adopting one. This is particularly true with C++, where the programming
language itself is intended to reduce the complexity involved in expressing a
program. This may in fact alleviate the need for ever-more-complex
methodologies. Instead, simpler ones may suffice in C++ for a much larger class
of problems than you could handle with simple methods for procedural languages.
It’s
also important to realize that the term “methodology” is often too
grand and promises too much. Whatever you do now when you design and write a
program is a method. It may be your own method, and you may not be conscious of
doing it, but it is a process you go through as you create. If it is an
effective process, it may need only a small tune-up to work with C++. If you
are not satisfied with your productivity and the way your programs turn out,
you may want to consider adopting a formal method, or choosing pieces from
among the many formal methods.
While
you’re going through the development process, the most important issue is
this: don’t get lost. It’s easy to do. Most of the analysis and
design methods
are intended to solve the largest of problems. Remember that most projects
don’t fit into that category, so you can usually have successful analysis
and design with a relatively small subset of what a method recommends. But some
sort of process, no matter how limited, will generally get you on your way in a
much better fashion than simply beginning to code.
It’s
also easy to get stuck, to fall into “analysis paralysis,” where
you feel like you can’t move forward because you haven’t nailed
down every little detail at the current stage. Remember that, no matter how
much analysis you do, there are some things about a system that won’t
reveal themselves until design time, and more things that won’t reveal
themselves until you’re coding, or not even until a program is up and
running. Because of this, it’s critical to move fairly quickly through
analysis and design to implement a test of the proposed system.
This
point is worth emphasizing. Because of the history we’ve had with
procedural languages, it is commendable that a team will want to proceed
carefully and understand every minute detail before moving to design and
implementation. Certainly, when creating a DBMS, it pays to understand a
customer’s needs thoroughly. But a DBMS is in a class of problems that is
very well-posed and well-understood. The class of programming problem discussed
in this chapter is of the “wild-card” variety, where it isn’t
simply re-forming a well-known solution, but instead involves one or more
“wild-card
factors” – elements where there is no well-understood previous
solution, and where research is necessary.
[10]
Attempting to thoroughly analyze a wild-card problem before moving into design
and implementation results in analysis paralysis
because you don’t have enough information to solve this kind of problem
during the analysis phase. Solving such a problem requires iteration through
the whole cycle, and that requires risk-taking behavior (which makes sense,
because you’re trying to do something new and the potential rewards are
higher). It may seem like the risk is compounded by “rushing” into
a preliminary implementation, but it can instead reduce the risk in a wild-card
project because you’re finding out early whether a particular design is
viable.
It’s
often proposed that you “build one to throw away.” With OOP, you
may still throw
part
of it away, but because code is encapsulated into classes, you will inevitably
produce some useful class designs and develop some worthwhile ideas about the
system design during the first iteration that do not need to be thrown away.
Thus, the first rapid pass at a problem not only produces critical information
for the next analysis, design, and implementation iteration, it also creates a
code foundation for that iteration.
That
said, if you’re looking at a methodology that contains tremendous detail
and suggests many steps and documents, it’s still difficult to know when
to stop. Keep in mind what you’re trying to discover:
What
are the objects? (How do you partition your project into its component parts?)
What
are their interfaces? (What messages do you need to be able to send to each
object?)
If
you come up with nothing more than the objects and their interfaces then you
can write a program. For various reasons you might need more descriptions and
documents than this, but you can’t really get away with any less.
The
process can be undertaken in four phases, and a phase 0 which is just the
initial commitment to using some kind of structure.
Phase
0: Make a plan
The
first step is to decide what steps you’re going to have in your process.
It sounds simple (in fact,
all
of this sounds simple) and yet people often don’t even get around to
phase one before they start coding. If your plan is “let’s jump in
and start coding,” fine. (Sometimes that’s appropriate when you
have a well-understood problem.) At least agree that this is the plan.
You
might also decide at this phase that some additional process structure is
necessary but not the whole nine yards. Understandably enough, some programmers
like to work in “vacation mode” in which no structure is imposed on
the process of developing their work: “It will be done when it’s
done.” This can be appealing for awhile, but I’ve found that having
a few milestones along the way helps to focus and galvanize your efforts around
those milestones instead of being stuck with the single goal of “finish
the project.” In addition, it divides the project into more bite-sized
pieces and make it seem less threatening (plus the milestones offer more
opportunities for celebrating).
When
I began to study story structure (so that I will someday write a novel) I was
initially resistant to the idea of structure, feeling that when I wrote I
simply let it flow onto the page. What I found was that when I wrote about
computers the structure was simple enough so that I didn’t need to think
much about it, but I was still structuring my work, albeit only
semi-consciously in my head. So even if you think that your plan is to just
start coding, you still go through the following phases while asking and
answering certain questions.
The
mission statement
Any
system you build, no matter how complicated, has a fundamental purpose, the
business that it’s in, the basic need that it satisfies. If you can look
past the user interface, the hardware- or system-specific details, the coding
algorithms and the efficiency problems, you will eventually find the core of
its being, simple and straightforward. Like the so-called
high
concept
from a Hollywood movie, you can describe it in one or two sentences. This pure
description is the starting point.
The
high concept is quite important because it sets the tone for your project;
it’s a mission statement. You won’t necessarily get it right the
first time (you may be in a later phase of the project before it becomes
completely clear), but keep trying until it feels right. For example, in an
air-traffic control system you may start out with a high concept focused on the
system that you’re building: “The tower program keeps track of the
aircraft.” But consider what happens when you shrink the system to a very
small airfield; perhaps there’s only a human controller or none at all. A
more useful model won’t concern the solution you’re creating as
much as it describes the problem: “Aircraft arrive, unload, service and
reload, and depart.”
Phase
1: What are we making?
In
the previous generation of program design (called
procedural
design
),
this is called “creating the requirements
analysis
and system
specification
.”
These, of course, were places to get lost: intimidatingly-named documents that
could become big projects in their own right. Their intention was good,
however. The requirements analysis says “Make a list of the guidelines we
will use to know when the job is done and the customer is satisfied.” The
system specification says “Here’s a description of
what
the program will do (not
how)
to satisfy the requirements.” The requirements analysis is really a
contract between you and the customer (even if the customer works within your
company or is some other object or system). The system specification is a
top-level exploration into the problem and in some sense a discovery of whether
it can be done and how long it will take. Since both of these will require
consensus among people, I think it’s best to keep them as bare as
possible – ideally, to lists and basic diagrams – to save time. You
might have other constraints that require you to expand them into bigger
documents, but by keeping the initial document small and concise, it can be
created in a few sessions of group brainstorming with a leader who dynamically
creates the description. This not only solicits input from everyone, it also
fosters initial buy-in and agreement by everyone on the team. Perhaps most
importantly, it can kick off a project with a lot of enthusiasm.
It’s
necessary to stay focused on the heart of what you’re trying to
accomplish in this phase: determine what the system is supposed to do. The most
valuable tool for this is a collection of what are called “use-cases.”
These are essentially descriptive answers to questions that start with
“What does the system do if ...” For example, “What does the
auto-teller do if a customer has just deposited a check within 24 hours and
there’s not enough in the account without the check to provide the
desired withdrawal?” The use-case then describes what the auto-teller
does in that situation.
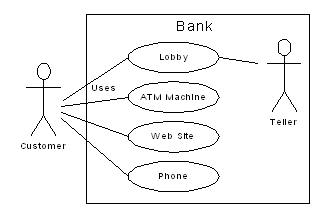
Use-case
diagrams are intentionally very simple, to prevent you from getting bogged down
in system implementation details prematurely:
Each
stick person represents an “actor,” which is typically a human or
some other kind of free agent (these can even be other computer systems). The
box represents the boundary of your system. The ellipses represent the use
cases themselves, which are units of functionality as they are perceived from
outside of the system. That is, it doesn’t matter how the system is
actually implemented, as long as it looks like this to the user.
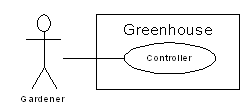
A
use-case does not need to be terribly complex, even if the underlying system is
complex. It is only intended to show the system as it appears to the user. For
example:
The
use cases produce the requirements specifications, by determining all the
interactions that the user may have with the system. You try to discover a full
set of use-cases for your system, and once you’ve done that you have the
core of what the system is supposed to do. The nice thing about focusing on
use-cases is that they always bring you back to the essentials and keep you
from drifting off into issues that aren’t critical for getting the job
done. That is, if you have a full set of use-cases you can describe your system
and move onto the next phase. You probably won’t get it all figured out
perfectly at this phase, but that’s OK. Everything will reveal itself in
the fullness of time, and if you demand a perfect system specification at this
point you’ll get stuck.
If
you get stuck, you can kick-start this phase by describing the system in a few
paragraphs and then looking for nouns and verbs. The nouns become either actors
or parts of use cases (or even entire use cases by themselves), and the verbs
become the interactions between the two. You’ll be surprised at how
useful a tool this can be; sometimes it will accomplish the lion’s share
of the work for you.
Use-cases
will identify key features in the system that will reveal some of the
fundamental classes you’ll be using. For example, if you’re in the
fireworks business, you may want to identify Workers, Firecrackers, and
Customers; more specifically you’ll need Chemists, Assemblers, and
Handlers; AmateurFirecrackers and ProfessionalFirecrackers; Buyers and
Spectators. Even more specifically, you could identify YoungSpectators,
OldSpectators, TeenageSpectators, and ParentSpectators.
Although
it’s a black art, at this point some kind of scheduling
can be quite useful. You now have an overview of what you’re building so
you’ll probably be able to get some idea of how long it will take. A lot
of factors come into play here: if you estimate a long schedule then the
company might not decide to build it, or a manager might have already decided
how long the project should take and will try to influence your estimate. But
it’s best to have an honest schedule from the beginning and deal with the
tough decisions early. There have been a lot of attempts to come up with
accurate scheduling techniques (like techniques to predict the stock market),
but probably the best approach is to rely on your experience and intuition. Get
a gut feeling for how long it will really take, then double that and add 10
percent. Your gut feeling is probably correct; you
can
get something working in that time. The “doubling” will turn that
into something decent, and the 10 percent will deal with final polishing and
details
[11].
However you want to explain it, and regardless of the moans and manipulations
that happen when you reveal such a schedule, it just seems to work out that way.
Phase
2: How will we build it?
In
this phase you must come up with a design that describes what the classes look
like and how they will interact. An excellent tool in determining classes and
interactions is the
Class-Responsibility-Collaboration
(CRC) card. Part of the value of this technique is that it’s so low-tech:
you start out with a set of blank 3” by 5” cards, and you write on
them. Each card represents a single class, and on the card you write:
The
name of the class. It’s important that this name capture the essence of
what the class does, so that it makes sense at a glance.
The
“responsibilities” of the class: what it should do. This can
typically be summarized by just stating the names of the member functions
(since those names should be descriptive in a good design), but it does not
preclude other notes. If you need to seed the process, look at the problem from
a lazy programmer’s standpoint: What objects would you like to magically
appear to solve your problem?
The
“collaborations” of the class: what other classes does it interact
with? “Interact” is an intentionally broad term; it could mean
aggregation or simply that some other object exists that will perform services
for an object of the class. Collaborations should also consider the audience
for this class. For example, if you create a class Firecracker, who is going to
observe it, a Chemist or a Spectator? The former will want to know what
chemicals go into the construction, and the latter will respond to the colors
and shapes released when it explodes.
You
may feel like the cards should be bigger because of all the information
you’d like to get on them, but they are intentionally small, not only to
keep your classes small but also to keep you from getting into too much detail
too early. If you can’t fit all you need to know about a class on a small
card, the class is too complex (either you’re getting too detailed, or
you should create more than one class). The ideal class should be understood at
a glance. The idea of CRC cards is to assist you in coming up with a first cut
on the design, so that you can get the big picture and refine the design.
One
of the great benefits of CRC cards is in communication. It’s best done
real-time, in a group, without computers. Each person takes responsibility for
several classes (which at first have no names or other information), and you
run a live simulation by going through your use-cases and deciding what
messages go to which objects to satisfy each use case. As you go through this
process, you discover the classes you need along with their responsibilities
and collaborations, and you fill out the cards as you do this. When
you’ve moved through all the use cases, you should have a fairly complete
first cut of your design.
Before
I began using CRC cards, the most successful consulting experiences I had when
coming up with an initial design involved standing in front of a team, who
hadn’t built an OOP project before, and drawing objects on a whiteboard.
We talked about how the objects should communicate with each other, and erased
some of them and replaced them with other objects (effectively, I was managing
all the “CRC cards” on the whiteboard). The team (who knew what the
project was supposed to do) actually created the design; they
“owned” the design rather than having it given to them. All I was
doing was guiding the process by asking the right questions, trying out the
assumptions and taking the feedback from the team to modify those assumptions.
The true beauty of the process was that the team learned how to do
object-oriented design not by reviewing abstract examples, but by working on
the one design that was most interesting to them at that moment: theirs.
Once
you’ve come up with a set of CRC cards, you may want to create a more
formal description of your design using UML. There are a fair number of books
on UML, and you can get the specification at
http://www.rational.com.
You don’t need to use UML, but it can be helpful, especially if you want
to put a diagram up on the wall for everyone to ponder, which is a good idea.
An alternative to UML is a textual description of the objects and their
interfaces, but this can be limiting.
UML
also provides a diagramming notation for describing the dynamic model of your
system, for situations where the state transitions of a system or subsystem are
dominant enough that they need their own diagrams (such as in a control
system), and for describing the data structures, for systems or subsystems
where data is a dominant factor (such as a database).
You’ll
know you’re done with phase 2 when you have described the objects and
their interfaces. Well, most of them – there are usually a few that slip
through the cracks and don’t make themselves known until phase 3. But
that’s OK. All you are concerned with is that you eventually discover all
of your objects. It’s nice to discover them early in the process but OOP
provides enough structure so that it’s not so bad if you discover them
later. In fact, the design of an object tends to happen in five stages,
throughout the process of program development.
Five
stages of object design
The
design life of an object is not limited to the period of time when you’re
writing the program. Instead, the design of an object appears over a sequence
of stages. It’s helpful to have this perspective because you stop
expecting perfection right away; instead, you realize that the understanding of
what an object does and what it should look like happens over time. This view
also applies to the design of various types of programs; the pattern for a
particular type of program emerges through struggling again and again with that
problem (design patterns are covered in Chapter XX). Objects, too, have their
patterns that emerge through understanding, use, and reuse.
1.
Object discovery.
This
stage occurs during the initial analysis of a program. Objects may be
discovered by looking for external factors and boundaries, duplication of
elements in the system, and the smallest conceptual units. Some objects are
obvious if you already have a set of class libraries. Commonality between
classes suggesting base classes and inheritance may appear right away, or later
in the design process.
2.
Object assembly.
As
you’re building an object you’ll discover the need for new members
that didn’t appear during discovery. The internal needs of the object may
require new classes to support it.
3.
System construction.
Once
again, more requirements for an object may appear at this later stage. As you
learn, you evolve your objects. The need for communication and interconnection
with other objects in the system may change the needs of your classes or
require new classes. For example, here you may discover the need for
facilitator or helper classes, such as a linked list, that contain little or no
state information and simply help other classes to function.
4.
System extension.
As
you add new features to a system you may discover that your previous design
doesn’t support easy system extension. With this new information, you can
restructure parts of the system, very possibly adding new classes or class
hierarchies.
5.
Object reuse.
This
is the real stress test for a class. If someone tries to reuse it in an
entirely new situation, they’ll probably discover some shortcomings. As
you change a class to adapt to more new programs, the general principles of the
class will become clearer, until you have a truly reusable type.
Guidelines
for object development
These
stages suggest some guidelines when thinking about developing your classes:
Let
a specific problem generate a class, then let the class grow and mature during
the solution of other problems.
Remember,
discovering the classes you need (and their interfaces) is the majority of the
system design. If you already had those classes, this would be an easy project.
Don’t
force yourself to know everything at the beginning; learn as you go.
That’s the way it will happen anyway.
Start
programming; get something working so you can prove or disprove your design.
Don’t fear procedural-style spaghetti code – classes partition the
problem and help control anarchy and entropy. Bad classes do not break good
classes.
Always
keep it simple. Little clean objects with obvious utility are better than big
complicated interfaces. When decision points come up, use a modified
Occam’s Razor approach: Consider the choices and select the one that is
simplest, because simple classes are almost always best. You can always start
small and simple and expand the class interface when you understand it better,
but as time goes on, it’s difficult to remove elements from a class.
Phase
3: Build it
This
is the initial conversion from the rough design to a compiling body of code
that can be tested, and especially that will prove or disprove your design.
This is not a one-pass process, but rather the beginning of a series of writes
and rewrites, as you’ll see in phase 4.
If
you’re reading this book you’re probably a programmer, so now
we’re at the part you’ve been trying to get to. By following a plan
– no matter how simple and brief – and coming up with design
structure before coding, you’ll discover that things fall together far
more easily than if you dive in and start hacking, and you’ll also
realize a great deal of satisfaction. Getting code to run and do what you want
is fulfilling, and can easily become an obsession. But it’s my experience
that coming up with an elegant solution is deeply satisfying at an entirely
different level; it feels closer to art than technology. And elegance
always pays off; it’s not a frivolous pursuit. Not only does it give you
a program that’s easier to build and debug, but it’s also easier to
understand and maintain, and that’s where the financial value lies.
After
you build the system and get it running, it’s important to do a reality
check, and here’s where the requirements analysis and system
specification comes in. Go through your program and make sure that all the
requirements are checked off, and that all the use-cases work the way
they’re described (an even better approach is to use the requirements
analysis and use-cases to generate test code). Now you’re done. Or are you?
Phase
4: Iteration
This
is the point in the development cycle that has traditionally been called
“maintenance,” a catch-all term that can mean everything from
“getting it to work the way it was really supposed to in the first
place” to “adding features that the customer forgot to
mention” to the more traditional “fixing the bugs that show
up” and “adding new features as the need arises.” So many
misconceptions have been applied to the term “maintenance” that it
has taken on a slightly deceiving quality, partly because it suggests that
you’ve actually built a pristine program and all you need to do is change
parts, oil it and keep it from rusting. Perhaps there’s a better term to
describe what’s going on.
The
term is iteration.
That is, “You won’t get it right the first time, so give yourself
the latitude to learn and to go back and make changes.” You might need to
make a lot of changes as you learn and understand the problem more deeply. The
elegance you’ll produce if you iterate until you get it right will pay
off, both in the short and the long term. Iteration is where your program goes
from good to great, and where those issues that you didn’t really
understand in the first pass become clear. It’s also where your classes
can evolve from single-project usage to reusable resources.
What
it means to “get it right” isn’t just that the program works
according to the requirements and the use-cases. It also means that the
internal structure of the code makes sense to you, and feels like it fits
together well, with no awkward syntax, oversized objects or ungainly exposed
bits of code. In addition, you must have some sense that the program structure
will survive the changes that it will inevitably go through during its
lifetime, and that those changes can be made easily and cleanly. This is no
small feat. You must not only understand what you’re building, but also
how the program will evolve (what I call the vector
of change
).
Fortunately, object-oriented programming languages are particularly adept at
supporting this kind of continuing modification – the boundaries created
by the objects are what tend to keep the structure from breaking down. They are
also what allow you to make changes – ones that would seem drastic in a
procedural program – without causing earthquakes throughout your code. In
fact, support for iteration might be the most important benefit of OOP.
With
iteration, you create something that at least approximates what you think
you’re building, and then you kick the tires, compare it to your
requirements and see where it falls short. Then you can go back and fix it by
redesigning and re-implementing the portions of the program that didn’t
work right.
[12]
You might actually need to solve the problem, or an aspect of the problem,
several times before you hit on the right solution. (A study of
Design
Patterns
,
described in Chapter XX, is usually helpful here.)
Iteration
also occurs when you build a system, see that it matches your requirements and
then discover it wasn’t actually what you
wanted.
When you see the system in operation, you find that you really wanted to solve
a different problem. If you think this kind of iteration is going to happen,
then you owe it to yourself to build your first version as quickly as possible
so you can find out if it’s what you want.
Iteration
is closely tied to incremental
development
.
Incremental development means that you start with the core of your system and
implement it as a framework upon which to build the rest of the system piece by
piece. Then you start adding features one at a time. The trick to this is in
designing a framework that will accommodate all the features you plan to add to
it. (See Chapter XX for more insight into this issue.) The advantage is that
once you get the core framework working, each feature you add is like a small
project in itself rather than part of a big project. Also, new features that
are incorporated later in the development or maintenance phases can be added
more easily. OOP supports incremental development because if your program is
designed well, your increments will turn out to be discrete objects or groups
of objects.
Perhaps
the most important thing to remember is that by default – by definition,
really – if you modify a class its super- and subclasses will still
function. You need not fear modification; it won’t necessarily break the
program, and any change in the outcome will be limited to subclasses and/or
specific collaborators of the class you change.
You
have to know when to stop iterating the design. Ideally, you achieve target
functionality and are in the process of refinement and addition of new features
when the deadline comes along and forces you to stop and ship that version.
(Remember, software is a subscription business.)
Plans
pay off
Of
course you wouldn’t build a house without a lot of carefully-drawn plans.
If you build a deck or a dog house, your plans won’t be so elaborate but
you’ll still probably start with some kind of sketches to guide you on
your way. Software development has gone to extremes. For a long time, people
didn’t have much structure in their development, but then big projects
began failing. In reaction, we ended up with methodologies that had an
intimidating amount of structure and detail, primarily intended for those big
projects. These methodologies were too scary to use – it looked like
you’d spend all your time writing documents and no time programming.
(This was often the case.) I hope that what I’ve shown you here suggests
a middle path – a sliding scale. Use an approach that fits your needs
(and your personality). No matter how minimal you choose to make it,
some
kind of plan will make a big improvement in your project as opposed to no plan
at all. Remember that, by most estimates, over 50 percent of projects fail
(some estimates go up to 70 percent!).
[10]
My rule of thumb for estimating such projects: If there’s more than one
wild card, don’t even try to plan how long it’s going to take or
how much it will cost. There are too many degrees of freedom.
[11]
My personal take on this has changed lately. Doubling and adding 10 percent
will give you a reasonably accurate estimate (assuming there are not too many
wild-card factors), but you still have to work quite dilligently to finish in
that time. If you actually want time to really make it elegant and to enjoy
yourself in the process, the correct multiplier is more like three or four
times, I believe.
[12]
This
is something like “rapid prototyping,” where you were supposed to
build a quick-and-dirty version so that you could learn about the system, and
then throw away your prototype and build it right. The trouble with rapid
prototyping is that people didn’t throw away the prototype, but instead
built upon it. Combined with the lack of structure in procedural programming,
this often leads to messy systems that are expensive to maintain.