Both TDFD as TDEFD have an extra menu in the main window called DFD which contains some commands that are specific for data flow diagrams.
Furthermore there is an editable text field labeled Diagram which shows the index of the data flow diagram. See section 6.1.3 for the function of that field.
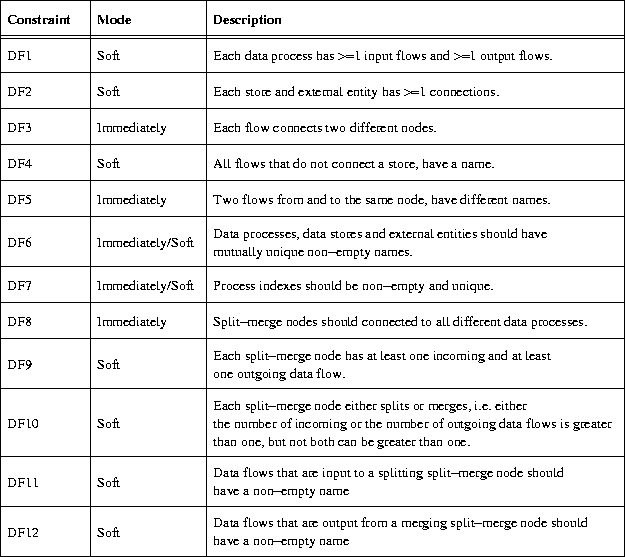
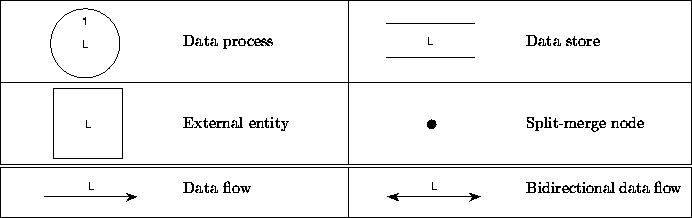
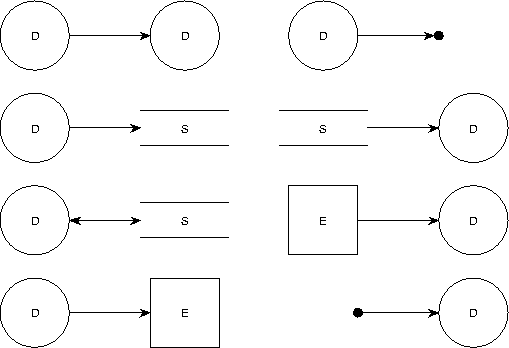
See figure 6.1 for the subjects and the representing shapes that are used in TDFD. In figure 6.2 you find the possible connections of node types by edge types. These are immediately enforced constraints.
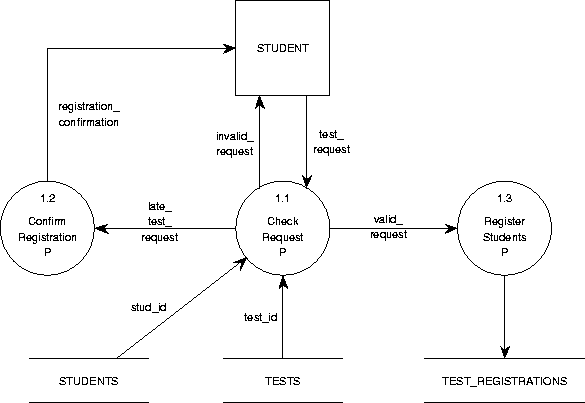
TDFD uses the standard data flow diagramming conventions from [5,22] with the exception that diagrams are always drawn as a graph in TCM and therefore, they can never have dangling edges. TDFD uses a different notation from the one being used in [18]: data flow diagrams should be drawn as a graph, so a flow in a decomposition going to or coming from ``nowhere'' is not permitted (unlike for instance [18], figures 9.16 and 9.17). See figure 6.3 for an example of the TCM notation for DFDs. For more information see appendix section C.3.1.
Data processes have unique indexes. Data process shapes show their index labels when the Indexes check button in the list of tiled node buttons is on . When you turn the toggle off, then the indexes become invisible and they cannot be edited. Index labels of data process shapes are positioned near the top of the circle. When they are visible, they can be edited separately from the name label by selecting it for editing by clicking in the upper part of the circle. TDFD immediately enforces that index labels are unique and that they conform to the BNF syntax in figure 6.4.
When you create a new data process, TDFD assigns it automatically a unique index number. By default TDFD assigns the processes the numbers one to the current number of processes. When you issue the command Renumber indexes from the DFD menu in the main window then all process indexes are renumbered to sequential indexes from one to the number of processes. When you create a new process, the lowest unused index number is chosen.
When you draw a leveled or hierarchical data flow diagrams, data processes can be decomposed into subdiagrams. If the diagram you are drawing is a decomposition of a data process with label n, then you can enter the label n in the text field labeled Diagram. When you fill in the text field, the index of the diagram is updated when you press <Return>. New processes that are created in the diagram receive then as index, the diagram index plus a unique number. For instance, when you have set the diagram index to 2 (i.e. the diagram is supposed to contain the decomposition of some data process with index 2), then all new processes will receive the indexes 2.1, 2.2, etc. So, when you edit a context diagram or a level 1 diagram then this field is empty. When you edit the diagram of a process decomposition then it contains the index of that process.
Warning: in the version of TCM that is described in this
manual you have to create for each decomposition a separate document.
In this version of TDFD it is
not possible to perform a decomposition within the editor.
Not even all invalid combinations of index and level numbers within
the same decomposition are checked yet ![[*]](foot_motif.gif) .
.
Data processes that are not decomposed are called primitive
data processes and should be specified by
a so-called minispec. In this version of TCM it is possible
to give a data process a minispec in the form of an arbitrary piece
of text. When you (first) select a data process and choose
the Minispec command from the DFD menu, then a text editor
dialog (see chapter 2.5)
is popped up in which you can edit a minispec in whatever notation
you prefer. Minispecs are stored together with the document and they
can be individually loaded and saved to file and
be printed .
In addition to the constraints that were mentioned in the previous sections of this chapter, TDFD also checks some other constraints that are summarized in figure 6.6. Some of these constraints can not be enforced immediately during all editor commands. If that is the case, they are additionally checked by Check Diagram as a soft constraint.
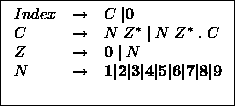
![\begin{figure}
\begin{center}
\begin{tabular}[t]
{c}
\subfigure []
{
\include...
...
\includegraphics {p/mergeexample.eps}
}
\end{tabular}\end{center}\end{figure}](img48.gif)